Приворотное зелье для Google: индексация и robots.txt (Часть №3)
Привет. Как дела? Слышал, твой сайт попал в индекс Google и на него стали заходить первые пользователи. Поздравляю! Следующий этап поисковой оптимизации заключается в ограничении поисковым машинам прав доступа к сайту, чтобы те ненароком не проиндексировали чего лишнего. Реализуется это посредством уже знакомых нам meta-тегов или специального файла, именуемого как robots.txt (встречаются, конечно, и более хитрые методы, но о них мы поговорим чуть позже).
Зачем нужен запрет индексации?
Запрет индексации нужен для исключения из поисковой выдачи страниц, которые не предназначены для общего доступа. К таким страницам можно отнести пользовательские профили с личной информацией, страницы с формами отправки информации, административный интерфейс и прочее. Однако стоит отметить, что блокировка страницы от индексации не гарантирует полного исключения из поисковой выдачи, если на нее ведет ссылка внутри сайта или из какого-либо внешнего ресурса.
Как запретить индексацию страниц при помощи meta-тегов?
Meta-тег robots, как правило, используется для запрета индексации страниц небольших сайтов (не более 15-20 страниц). Чтобы заблокировать какую-либо из страниц сайта для индексации, всего-то нужно добавить внутри тега head строку следующего содержания: <meta name=«robots» content=«noindex,nofollow»>.
Выглядит это следующим образом:
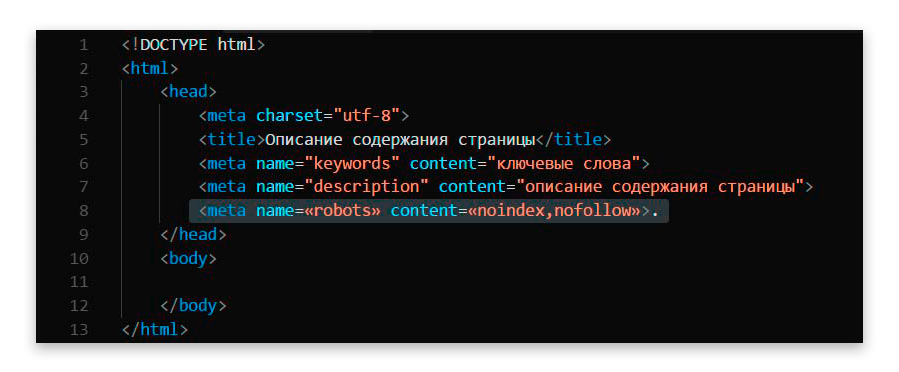
Как запретить индексацию страниц при помощи robots.txt?
Блокировка страниц для индексации посредством robots.txt производится немного сложнее, нежели при помощи meta-тегов. Однако в случае с интернет-магазинами, торговыми площадками и прочими крупными web-порталами она гораздо удобнее, так как дает возможность в одном документе просматривать все исключения и правила для поисковых машин.
Robots.txt – индексный файл в кодировке UTF-8, предоставляющий поисковым машинам информацию о том, какие страницы или файлы подлежат или не подлежат сканированию. Создать robots.txt можно практически в любом текстовом редакторе, будь то стандартный для «Блокнот» или Microsoft Word.
В большинстве случаев robots.txt состоит из таких правил, как:
- user-agent – перечень роботов, для которых описывались инструкции;
- disallow – перечень страниц и файлов, которые не подлежат сканированию;
- allow – перечень страниц и файлов, которые подлежат сканированию.
Выглядит это следующим образом:
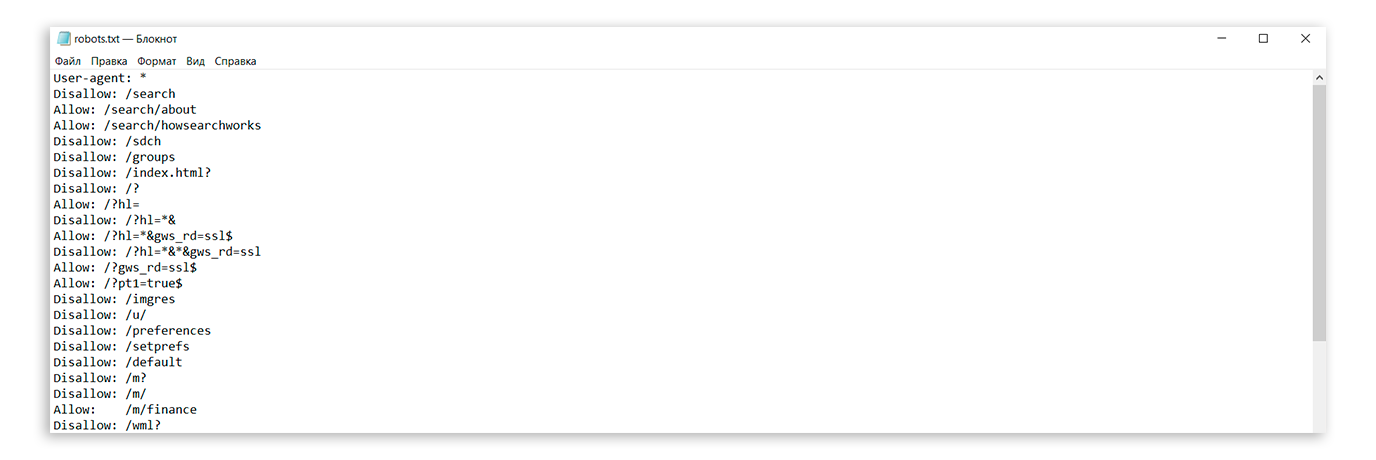
Примечание! Правила disallow и allow сканируются в порядке возрастания по длине префикса URL и применяются последовательно. В случаях, когда на одну страницу действует сразу несколько правил, актуальным для поисковых машин будет последнее правило из списка.
Ознакомиться с тонкостями оформления файла robots.txt можно по ссылке http://www.robotstxt.org/robotstxt.html или на русскоязычных тематических формах. Также всегда можно обратиться за подобной услугой к нам – мы сделаем все в лучшем виде и, при необходимости, проконсультируем о тонкостях проделанной работы.
Продолжение следует…
Автор:
Никита Логинов
Обсудить проект
Крутые проекты начинаются с заполнения этой формы